TCP Fast Open is fascinating!
Published on
It’s been a long time since I did a blog post. To be frank, I encountered tons of fascinating tech, but never got around to creating blog posts, since they took more time then I wanted to invest and also considered giving the site a redesign.
But in the meantime I’ll try to post more frequently. I’ll try to keep those blog posts shorter so I will be compelled to do more in the future. And this seems like a perfect topic to start on.
While learning a ton about http2 and http3, I did some nginx optimizations. I finally understood some config entries more and went ham on optimizing stuff. While doing so I stumbled upon the various available options for the listen directive.
One of those was the fastopen parameter. There is a great article over at lwn.net. In a nutshell, this enabled the use of a special cookie, that can in turn be used to remove the time of one roundtrip from the 3-way tcp handshake by sending data in the first syn packet and authorizing this by use use of an previously received cookie (if the client requested it and the server supports/allows it).
TCP Fastopen support can be looked up on linux using a sysctl value: cat /proc/sys/net/ipv4/tcp_fastopen.
A value of 0 seems to indicate no support (or just disabled?). A 1 means it is supported/enabled for the client side. To enable it to work on the server side, we set the sysctl to 3 (2nd bit = server side can use fastopen).
The easiest way is to create a config in /etc/sysctl.d/ and set net.ipv4.tcp_fastopen=3. You can apply this with sudo sysctl --system (and test your config while on it).
In nginx you should then be able to add fastopen=256 to your first listen directive (256 seems like a commonly used value). Since this is a option that affects the raw socket, you can likely only set this for your first listen directive (ipv4 and ipv6 respectively). Best to add it to your listen directive that also has default_server/default set.
Should nginx complain, you have probably set it too often. Note that nginx seems to lump specific addresses under 0.0.0.0 or [::] if you used that. So only specify it for these then. A good check is to see what sockets nginx bound your addresses to using e.g. ss -tlnp | grep 443.
For IPv6 it seems to me, that there is no special configuration necessary. From my testing, it seems to be available by default (also no obvious way to control it like for ipv4).
Is it really necessary?
Not really. Especially when using a browser and already having http2 support this will not make much sense, since you’re using a long-lived connection anyway.
If you use the experimental nginx-quic build, a HTTP3 client will also not use it, since http3 uses udp (the QUIC protocol).
However for small http clients that cannot keep the same connection open and do multiple small requests, this can have a sizable improvement.
Testing
The most reliable way seems to use curl.
Here I did a test to a server to which I have a ping of about 45-55ms.
I then did a curl to a simple resource. Once without fastopen used, and once with.
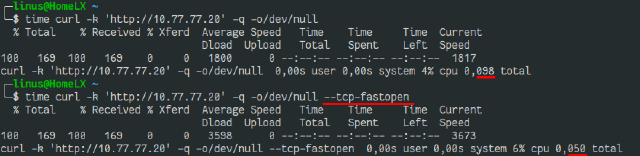
As you can see in the total times, the 2nd request only took one round trip to complete. This is a huge improvement.
But in more likely cases, you’ll not see this massive improvement, as TLS and DNS also demand their bit.
A pretty simple test with https still yielded a 25% improvement:
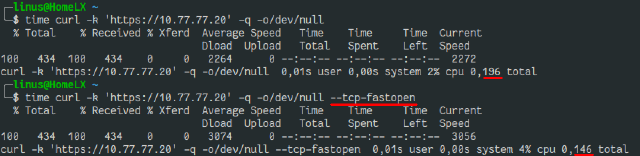
Note: The vpn connection used, should only add fractions of a millisecond in this case and spared me to look up the public ip (to avoid dns).
Viewing it in wireshark is also pretty interesting:
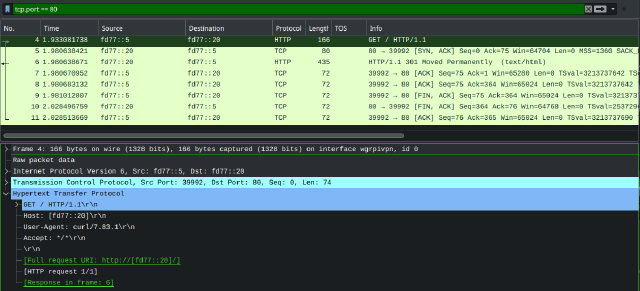
Here, the tcp connection already has a cookie. The very first packet therefore already includes the entire message. This makes it a very odd sight, as wireshark doesn’t display it as a TCP | [SYN] packet. It is both the TCP-Syn packet, but also contains the entire HTTP Request as well (hence wireshark shows it as HTTP instead).
The server then can respond with a TCP SynAck followed by the HTTP Response as well. The remaining packets don’t contain any user data anymore and just lead the the connection being closed. It should probably also be possible to combine a lot of those packets as well (e.g. the SynAck + Response).
Not sure if this would be possible, but having the server response with SynAck, HTTP Response and also the Fin flag would sure be funny. That could make the exchange only 3 packets (or even 2 of the server rudely wouldn’t care about the client confirming the FinAck of the connection). Maybe QUIC could be that close to perfection already? I’ll leave this for another day to figure out…